Deploy to On-premise
This tutorial will guide you through the process when you have your own on-premise servers, and want to deploy the model cards to those servers.
Bind your devices to TensorOpera AI Platform
Bind your device to TensorOpera AI Platform.
fedml login $api_key
## Example output
Welcome to FedML.ai!
Start to login the current device to the FedML® Nexus AI Platform
You can also see your device id on TensorOpera AI Platform.
Deploy the model card to the on-premise device
Suppose you have pushed and checked the Model Card's existence on TensorOpera AI Platform
Otherwise follow the previous chapter to use fedml model create and fedml model push command to create and push a local model card to TensorOpera AI Platform.
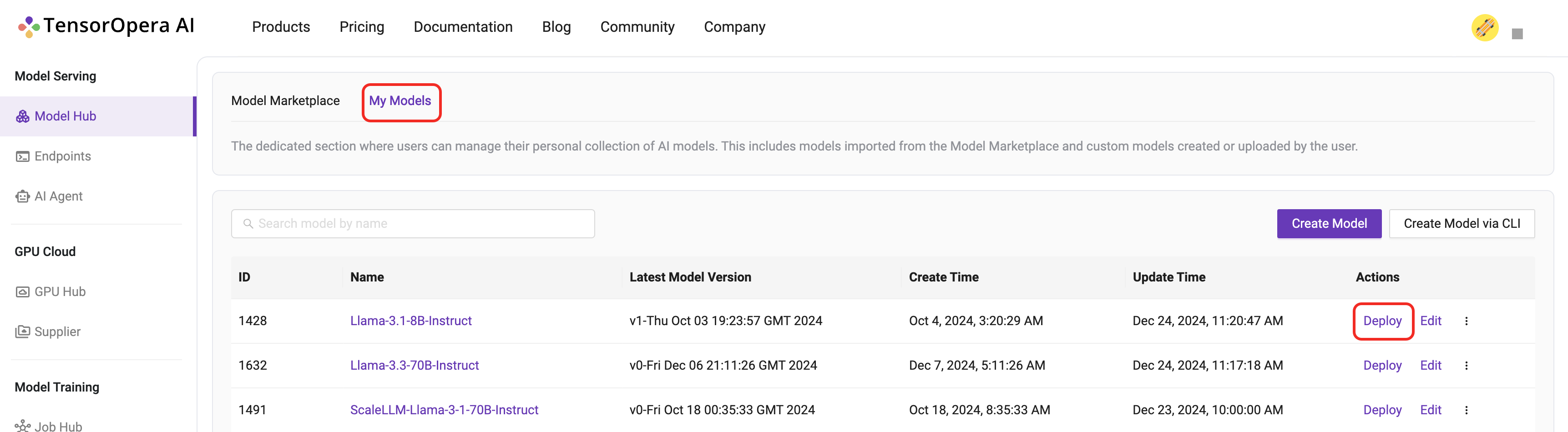
Check if the model card is uploaded to TensorOpera AI Platform by clicking the Model Serving -> Model Hub -> My Models tab on the TensorOpera AI Platform dashboard, then click the Deploy button on the UI.
In the deployment page, select one master device and some worker (>=1) devices to deploy the model card. you can also configure the deployment settings, like the resource allocation, the number of replicas, etc.
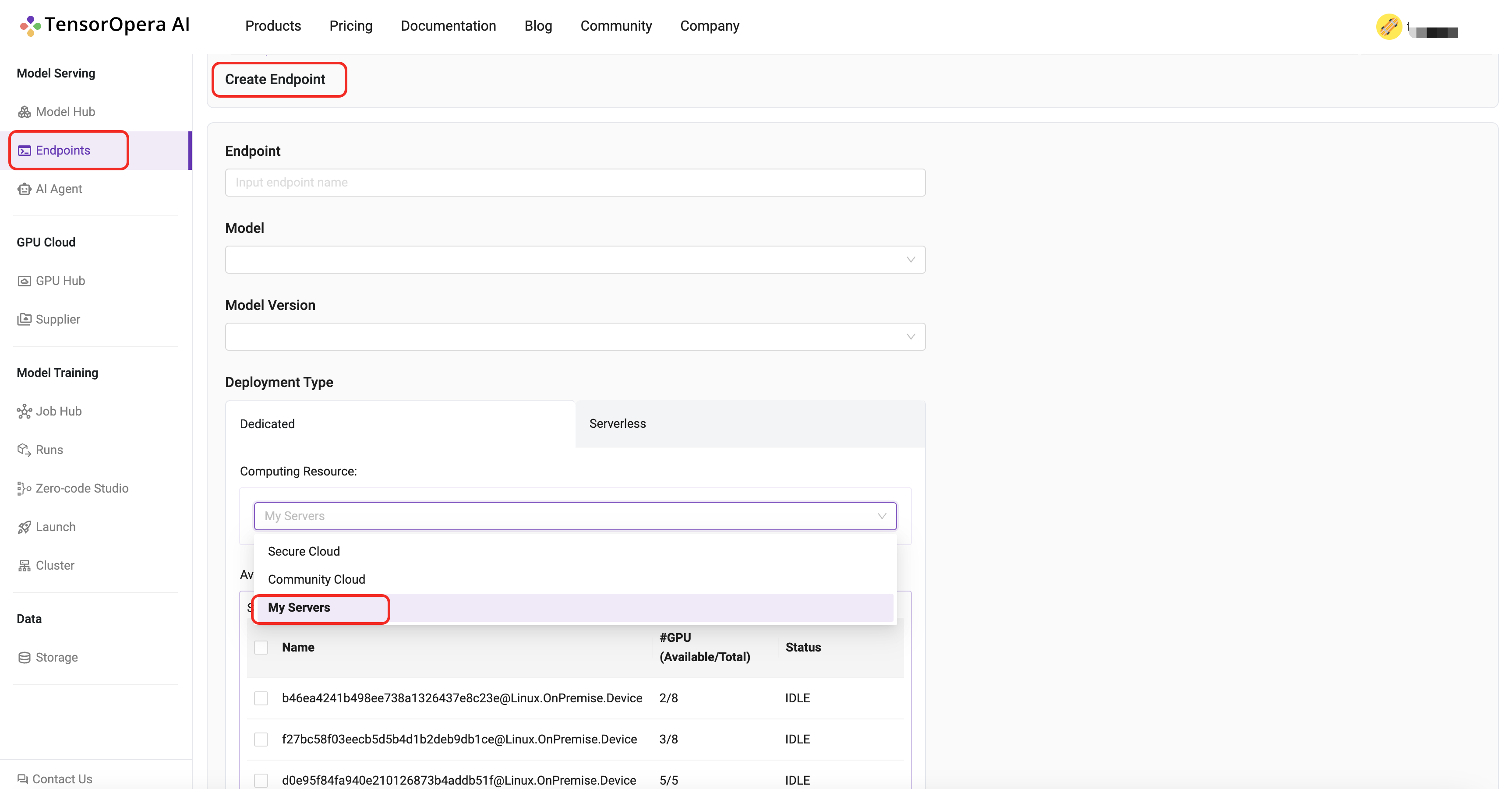
Click the deploy button after you select the corresponding options. After few minutes, the model will be deployed to your own on-premise servers. You can find the deployment details in the Model Serving -> Endpoints tab in the TensorOpera AI Cloud dashboard.