Deploy to Cloud
This tutorial will guide you through the process of deploying a model card to a decentralized serverless GPU cloud.
Select the model card
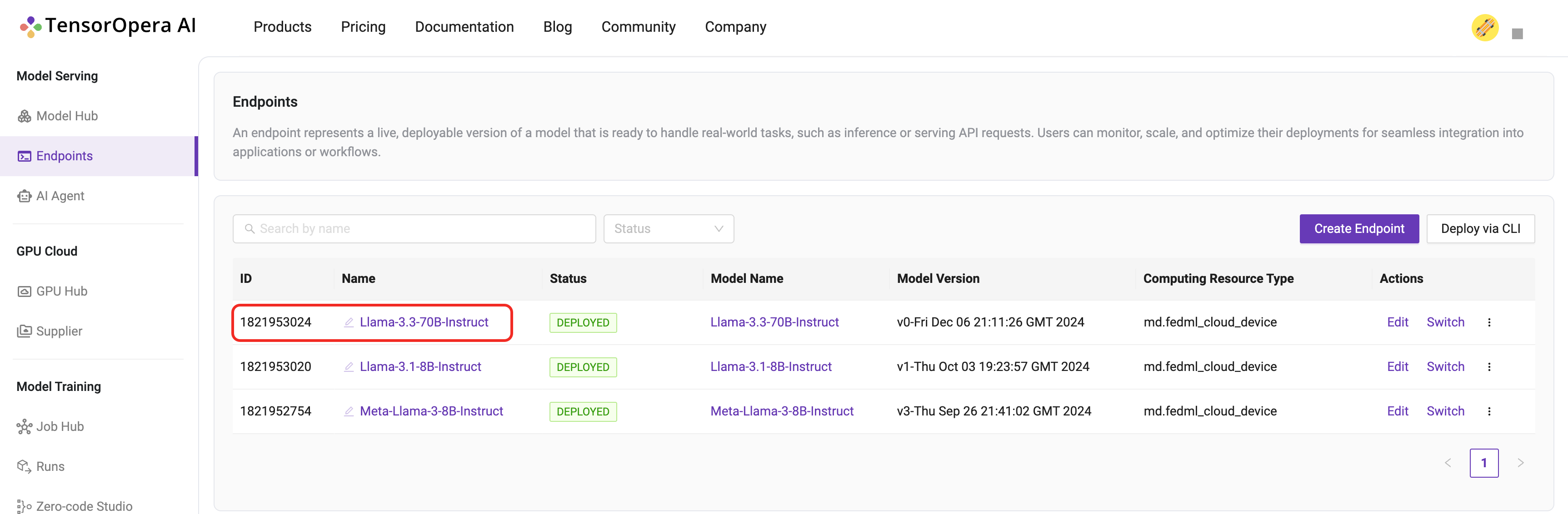
Suppose you have pushed and checked the Model Card's existence on TensorOpera AI Platform
Otherwise follow the previous chapter to use fedml model create and fedml model push command to create and push a local model card to TensorOpera AI Platform.
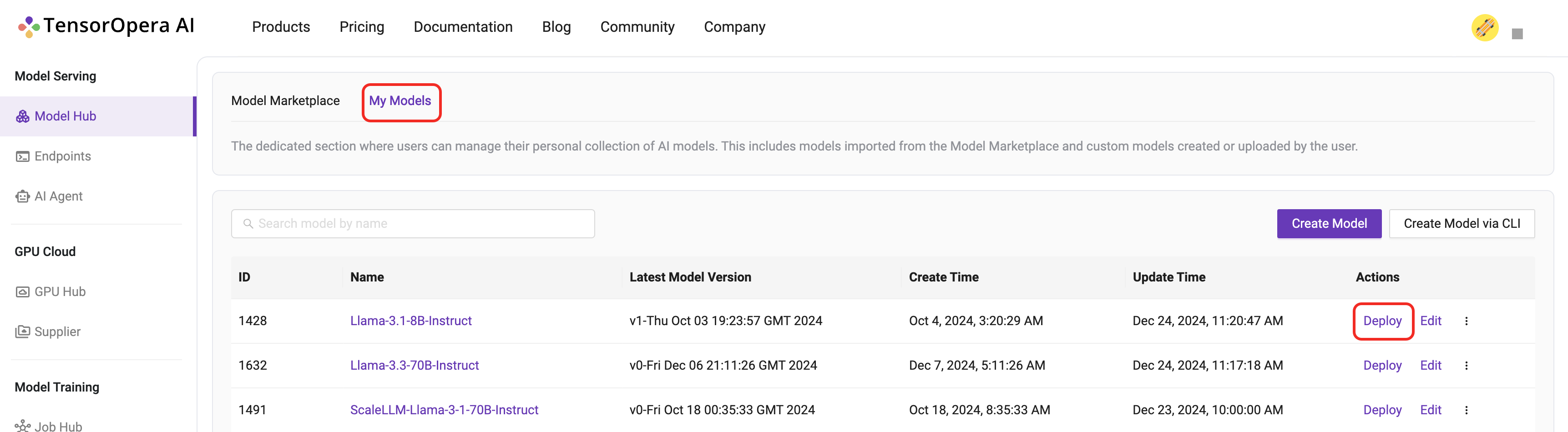
Check if the model card is uploaded to TensorOpera AI Platform by clicking the "Deploy" -> "My Models" tab on the TensorOpera AI Platform dashboard, then click the "Deploy" button on the UI.
Config the endpoint
In the endpoint configuration page, you can configure the deployment settings, like the resource allocation, the number of replicas, etc.
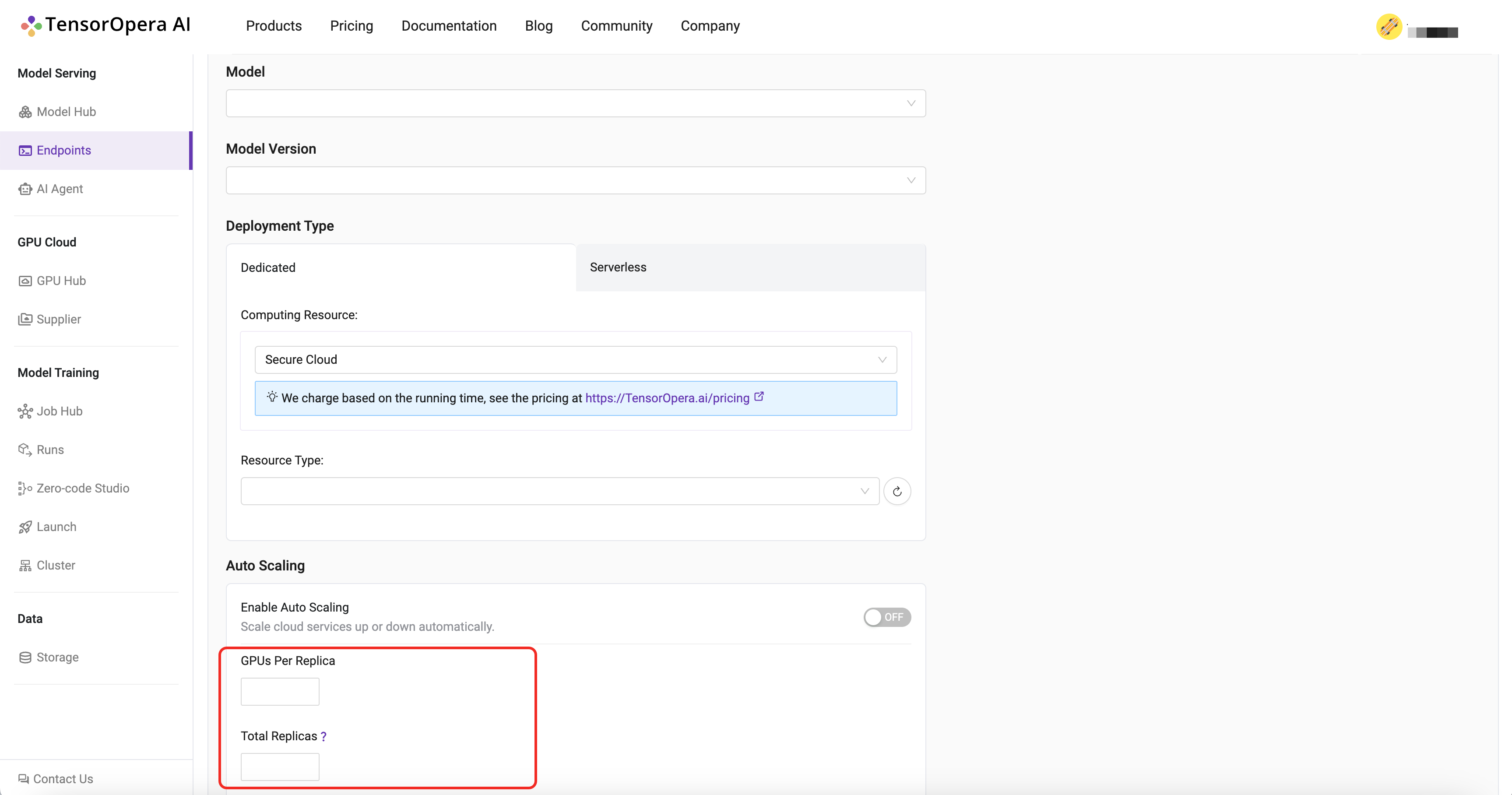
What is a Dedicated Endpoint?
Here the Dedicated Endpoint means you are using the following two type of devices, includes:
- On-premise device
- Cloud device that TensorOpera allocated to you.
The charges are based on the usage of the device.
For more endpoint price details, please contact us https://tensoropera.ai/contact for more information.
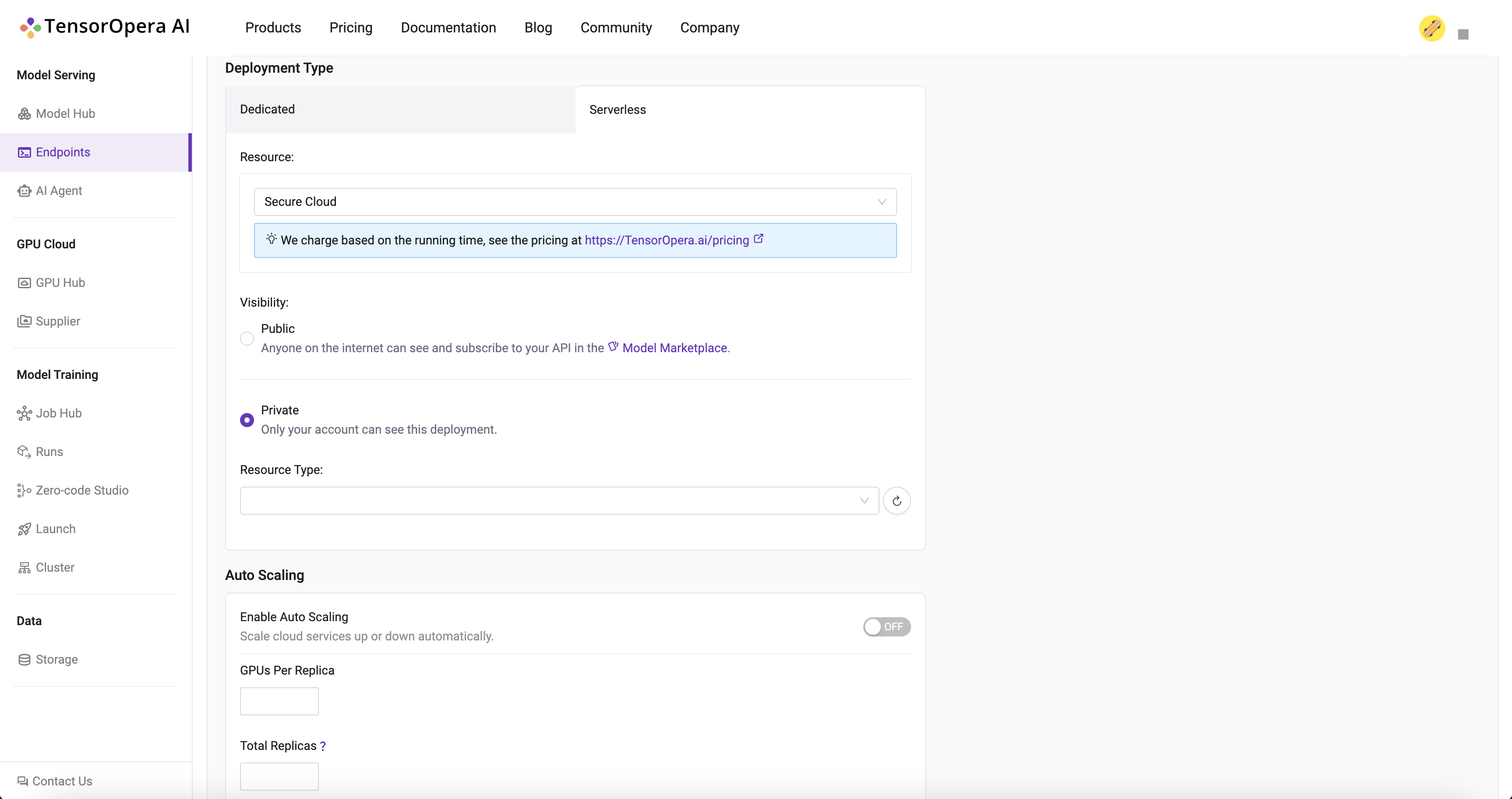
What is a Serverless Endpoint?
There are two difference from Dedicated Endpoint.
- This endpoint can be published on Model Marketplace which can be used / paid by other users.
- The charges are based on the usage of the endpoints, say tokens usage in LLM model.
For more endpoint price details, please contact us https://tensoropera.ai/contact for more information.
Deploy to the Cloud Devices
Click the deploy button after you select the corresponding options. After few minutes, the model will be deployed to the decentralized serverless GPU cloud. You can find the deployment details in the Model Serving -> Endpoints tab in the TensorOpera AI Cloud dashboard.