Benchmarking results when using single process-based simulation
| Dataset | Model | Accuracy (Exp/Ref) |
|---|---|---|
| MNIST | LR | 81.9 / |
| Federated EMNIST | CNN | 80.2 / 84.9 |
| fed_CIFAR100 | ResNet | 34.0 / 44.7 |
| shakespeare (LEAF) | RNN | 53.1 / |
| fed_shakespeare (Google) | RNN | 57.1 / 56.9 |
| stackoverflow_nwp | RNN | 18.3 / 19.5 |
Note: Experimental results are the test accuracy of the last communication rounds, while the reference results are the validation results from referenced paper.
Hyper-parameters to reproduce the benchmarking results (non-IID)
MNIST + Logistic Regression
data_args:
dataset: "mnist"
partition_method: "hetero"
partition_alpha: 0.5
model_args:
model: "lr"
train_args:
federated_optimizer: "FedAvg"
client_id_list: "[]"
client_num_in_total: 1000
client_num_per_round: 10
comm_round: 200
epochs: 1
batch_size: 10
client_optimizer: sgd
learning_rate: 0.03
The reference experimental result: https://app.wandb.ai/automl/fedml/runs/ybv29kak
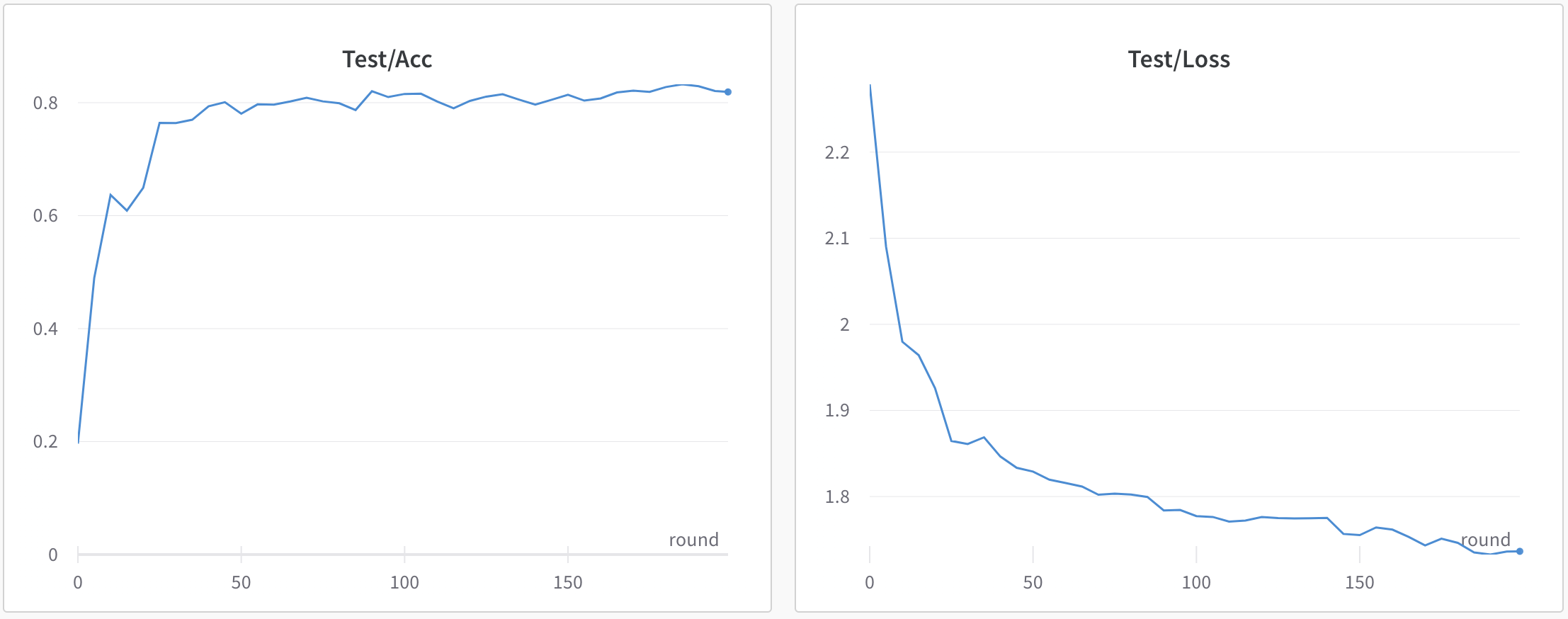
Shakespeare (LEAF) + RNN
data_args:
dataset: "mnist"
partition_method: "hetero"
partition_alpha: 0.5
model_args:
model: "lr"
train_args:
federated_optimizer: "FedAvg"
client_id_list: "[]"
client_num_in_total: 10
client_num_per_round: 10
comm_round: 10
epochs: 1
batch_size: 10
client_optimizer: sgd
learning_rate: 0.8
The experimental result refers to:https://app.wandb.ai/automl/fedml/runs/2al5q5mi

Shakespeare (Google) + RNN
data_args:
dataset: "shakespeare"
partition_method: "hetero"
partition_alpha: 0.5
model_args:
model: "lr"
train_args:
federated_optimizer: "FedAvg"
client_id_list: "[]"
client_num_in_total: 10
client_num_per_round: 10
comm_round: 1000
epochs: 1
batch_size: 10
client_optimizer: sgd
learning_rate: 0.8
The experimental result refers to:https://wandb.ai/automl/fedml/runs/4btyrt0u

Federated EMNIST + CNN
data_args:
dataset: "femnist"
partition_method: "hetero"
partition_alpha: 0.5
model_args:
model: "lr"
train_args:
federated_optimizer: "FedAvg"
client_id_list: "[]"
client_num_in_total: 10
client_num_per_round: 10
comm_round: 1000
epochs: 1
batch_size: 20
client_optimizer: sgd
learning_rate: 0.03
The experimental result refers to:https://wandb.ai/automl/fedml/runs/3lv4gmpz

Fed-CIFAR100 + CNN
data_args:
dataset: "fed_cifar100"
partition_method: "hetero"
partition_alpha: 0.5
model_args:
model: "resnet18_gn"
train_args:
federated_optimizer: "FedAvg"
client_id_list: "[]"
client_num_in_total: 10
client_num_per_round: 10
comm_round: 4000
epochs: 1
batch_size: 10
client_optimizer: sgd
learning_rate: 0.1
The experimental result refers to:https://wandb.ai/automl/fedml/runs/1canbwed
Stackoverflow + Logistic Regression
data_args:
dataset: "stackoverflow_lr"
partition_method: "hetero"
partition_alpha: 0.5
model_args:
model: "lr"
train_args:
federated_optimizer: "FedAvg"
client_id_list: "[]"
client_num_in_total: 10
client_num_per_round: 10
comm_round: 2000
epochs: 1
batch_size: 10
client_optimizer: sgd
learning_rate: 0.03
The experimental result refers to:https://wandb.ai/automl/fedml/runs/3aponqml
Stackoverflow + RNN
data_args:
dataset: "stackoverflow_nwp"
partition_method: "hetero"
partition_alpha: 0.5
model_args:
model: "rnn"
train_args:
federated_optimizer: "FedAvg"
client_id_list: "[]"
client_num_in_total: 10
client_num_per_round: 10
comm_round: 2000
epochs: 1
batch_size: 10
client_optimizer: sgd
learning_rate: 0.03
The experimental result refers to: https://wandb.ai/automl/fedml/runs/7pf2c9r2
CIFAR-10 + ResNet-56
data_args:
dataset: "cifar10"
partition_method: "hetero"
partition_alpha: 0.5
model_args:
model: "resnet56"
train_args:
federated_optimizer: "FedAvg"
client_id_list: "[]"
client_num_in_total: 10
client_num_per_round: 10
comm_round: 200
epochs: 1
batch_size: 10
client_optimizer: sgd
learning_rate: 0.03